
Wie die meisten Branchen ist auch der Journalismus von den rasanten technischen Entwicklungen im Feld der Künstlichen Intelligenz (KI) betroffen. Einerseits bieten sich viele neue Möglichkeiten, Arbeitsprozesse zu erleichtern oder gar gänzlich zu automatisieren. Anderseits bleiben viele Fragen offen, ob und vor allem wie KI in der Recherche und Berichterstattung eingesetzt werden kann, ohne Prinzipien des Journalismus zu verletzen.
Vor allem der investigative Journalismus hat sich im zurückliegenden Jahrzehnt wiederholt mit Recherchen in gigantischen Datenmengen befasst. Die Panama Papers (2016), die Paradise Papers (2017) und die Pandora Papers (2021) stehen beispielhaft für diese Art von Recherchen, bei denen tausende Gigabyte an Daten ausgewertet werden — in diesen Fällen, um Offshore-Geschäfte von Superreichen sowie Briefkastenfirmen und internationale Finanzströme zur Steuervermeidung aufzudecken.
Um die enorme Menge an Daten auszuwerten, schließen sich bei dieser Art von Recherchen häufig große Medien zusammen. Hunderte Journalistinnen und Journalisten aus vielen Ländern arbeiten gemeinsam an der Auswertung.
Technische Hilfen für investigative Recherche
Neue technische Möglichkeiten helfen bereits dabei, die enormen Datenbestände auszuwerten. Dazu gehören relativ simple Schlagwortsuchen genauso wie Knowledge Graphs. Diese erlauben es, die in den zugrunde liegenden Dokumenten bestehenden Beziehungen und Muster zu erkennen, die für menschliche Rechercheure aufgrund des schieren Umfangs der Daten nicht offensichtlich wären.
Maschinelles Lernen und andere Teilbereiche Künstlicher Intelligenz können Zusammenhänge aufdecken, die auf den ersten Blick verborgen bleiben. Dadurch können sie investigative Geschichten fördern, die sonst vielleicht unentdeckt geblieben wären. Diese Fähigkeit zur Mustererkennung ist besonders wertvoll in investigativen Journalismusprojekten, wo die Verbindung zwischen verschiedenen Entitäten und Ereignissen oft den Unterschied zwischen einer alltäglichen Geschichte und einer bahnbrechenden Enthüllung ausmacht.
Suche nach Bedeutung statt nach Wörtern
Neben dieser strukturierten Mustererkennung können aber auch Methoden aus der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) bei der Erschließung großer Textmengen helfen. Denn während beispielsweise Schlagwortsuchen allein auf konkrete Zeichenkombinationen (Wörter, Wortkombinationen, Sätze) schauen können — in der Linguistik nennt sich dies “Syntaktik” —, erlauben andere Verfahren, sich auf Bedeutungen und Konzepte zu fokussieren. Dieser Teilbereich der Linguistik heißt “Semantik”, weshalb man darauf basierende Suchen auch “semantische Suche” nennt.
Was bedeutet das konkret? Nehmen wir an, jemand sucht nach Informationen über „Klimawandel“. Bei einer traditionellen Schlagwortsuche würden nur Fundstellen angezeigt, die genau diesen Begriff enthalten. Eine semantische Suche hingegen versteht, dass damit auch Themen wie „globale Erwärmung“, „Treibhauseffekt“ oder „CO2-Emissionen“ gemeint sein können, auch wenn das exakte Schlagwort „Klimawandel“ nicht im Text vorkommt.
So könnte eine semantische Suche einen Artikel über „die Auswirkungen erhöhter CO2-Werte auf die Ozeantemperaturen“ als relevant erkennen, selbst wenn das Wort „Klimawandel“ dort nie direkt erwähnt wird. Dies ermöglicht Nutzer:innen, umfassendere und tiefgründigere Informationen zu ihrem Suchthema zu erhalten, da die Suche die Bedeutung hinter den Wörtern erfasst und berücksichtigt.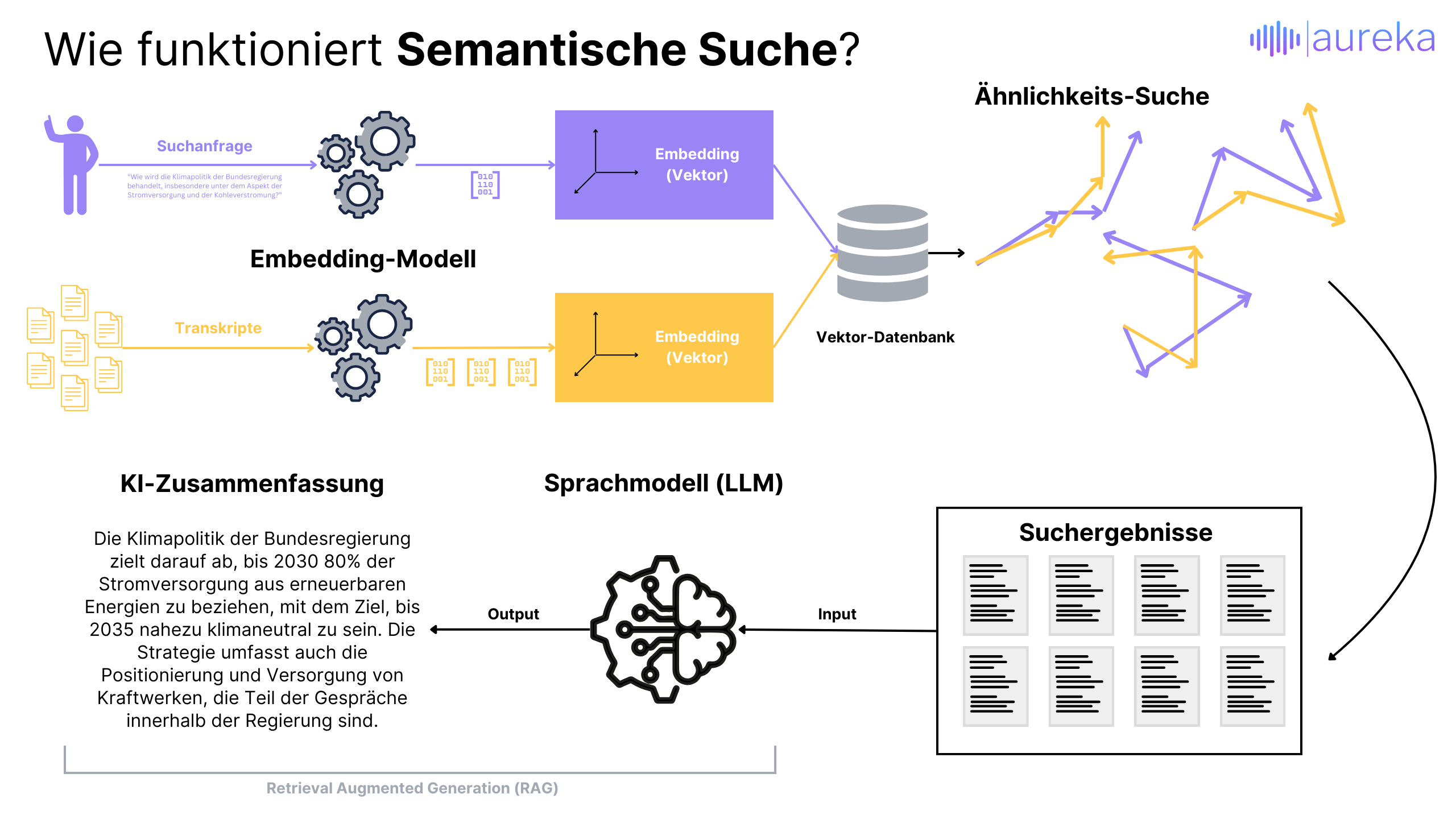
Wie funktioniert eine semantische Suche?
Man kann sich vorstellen, dass jedes Wort oder jeder Satz in eine Art Pfeil umgewandelt wird, der in eine Richtung zeigt. In der Realität der Computer passiert dies in einem komplexen Raum mit beliebig vielen Dimensionen, den wir uns nicht wirklich vorstellen können. Diese Pfeile, die „(Vector) Embeddings“ oder vereinfacht Vektoren genannt werden, repräsentieren nicht die Position der Wörter oder Sätze im Raum, sondern ihre Bedeutung.
Wenn wir eine Suchanfrage stellen, wandelt der Computer auch diese in einen solchen Vektor um. Um passende Ergebnisse zu finden, sucht der Computer dann nach Vektoren, die in eine ähnliche Richtung zeigen oder nahe beieinander im Raum liegen. Dieser Prozess ermöglicht es, die semantische Ähnlichkeit zwischen einer Suchanfrage und den vorhandenen Informationen zu bestimmen.
Der Schlüssel liegt darin, dass nicht nach exakten Wortübereinstimmungen gesucht wird, sondern nach Bedeutungen, die sich in der Ausrichtung und Position der Pfeile im multidimensionalen Raum widerspiegeln. So kann die semantische Suche Inhalte finden, die ähnliche Themen oder Ideen behandeln, selbst wenn die exakten Wörter unserer Anfrage dort nicht vorkommen.
Retrieval Augmented Generation (RAG)
Und man kann es noch weiter treiben. In einem nächsten Schritt kann man die Suchergebnisse, also die Stellen aus dem Originalmaterial mit hoher semantischer Ähnlichkeit zur Suchanfrage, als Eingabe in ein generatives Sprachmodell verwenden. Deren Fähigkeit, Text zu “verstehen” und darauf basierende Antworten zu geben, kann man sich auch bei der Erschließung großer Datenmengen zunutze machen.
Das Prinzip dahinter nennt sich Retrieval Augmented Generation (RAG, auf deutsch etwa “Abrufgestützte Erzeugung”). Dabei geht es darum, die besten Suchergebnisse – also die Textstellen, die am meisten mit der gestellten Frage übereinstimmen – als Grundlage zu nehmen und diese Informationen dann einem generativen Sprachmodell (wie zum Beispiel GPT-4 oder BERT) zu übergeben.
Das Besondere an RAG ist, dass es quasi eine Brücke schlägt: Es holt sich zuerst die relevanten Informationen aus einer riesigen Datenmenge und nutzt diese dann, um eine neue, auf der Suchanfrage basierende Antwort zu erstellen. Das Sprachmodell "liest" quasi die ausgewählten Textstellen und formuliert daraufhin eine Antwort, die nicht nur auf allgemeinem Wissen basiert, sondern speziell auf den Informationen aus den Suchergebnissen. So entstehen Antworten, die tiefer gehen und spezifischer auf die gestellte Frage eingehen können, als wenn das Modell nur sein vorab gelerntes Wissen verwenden würde.
Dieser Ansatz kombiniert also das Beste aus zwei Welten: die Fähigkeit, relevante Informationen aus großen Datenmengen herauszufiltern, und die Kapazität, diese Informationen zu verstehen und in eine sinnvolle, zusammenhängende Antwort zu integrieren.
Semantische Suche bei aureka
Ganz ähnlich machen wir es bei aureka. In Zukunft werden alle Transkripte, Metadaten und Annotationen (Anmerkungen), die in unsere Plattform hochgeladen werden, nach semantischer Bedeutung durchsuchbar sein. Egal ob es sich um zehn transkribierte Interviews oder deutlich größere Datenmengen handelt: Mit unseren semantischen Suche können Stellen im Originalmaterial noch besser und präziser gefunden werden. Möglich macht es die oben beschriebene semantische Suche.
Dies wird auch Journalist:innen und Podcastpoduzent:innen helfen, zielgenauer Stellen im transkribierten Rohmaterial oder anderen Materialien zu finden und dann weiterzuverwenden.
